P值公式|分步示例以计算P值
什么是P值公式?
P是一种统计量度,可帮助研究人员确定其假设是否正确。它有助于确定结果的重要性。零假设是默认位置,即两个测得的现象之间没有任何关系。用H表示0.另一种 如果原假设被认为是不正确的,那么假设就是您会相信的假设。它的符号是H1 或H一种。
excel中的P值是介于0和1之间的数字。有表格,电子表格程序和统计软件可帮助计算P值。显着性水平(α)是研究人员设定的预定义阈值。通常为0.05。小于显着性水平的非常小的p值表示您拒绝原假设。大于显着性水平的P值表示我们无法拒绝原假设。
P值公式的说明
可以使用以下步骤来得出p值的计算公式:
根据Z统计量计算P值
步骤1: 我们需要找出检验统计量z


在哪里
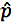 是样本比例
是样本比例- p0是零假设中的假定人口比例
- n是样本量
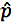 是样本比例
是样本比例第2步: 我们需要从获得的z值中找到相应的p级别。为此,我们需要查看z表。

来源: www.dummies.com
例如,让我们找到对应于z≥2.81的p的值。由于正态分布是对称的,因此z的负值等于其正值。 2.81是2.80和0.01的总和。查看z列中的2.8和对应的值0.01。我们得到p = 0.0025。
P值公式的示例(带有Excel模板)
让我们看一下P值方程的一些简单到高级的例子,以更好地理解它。
您可以在此处下载此P值公式Excel模板– P值公式Excel模板
范例#1
a)P值为0.3015。如果显着性水平为5%,请确定我们是否可以拒绝原假设。
b)P值为0.0129。如果显着性水平为5%,请确定我们是否可以拒绝原假设。
解决方案:
使用以下数据计算P值。

P值将为–

a)由于0.3015的p值大于0.05的显着性水平(5%),因此我们无法拒绝原假设。
b)由于0.0129的p值小于0.05的显着性水平,因此我们拒绝原假设。
范例#2
根据一项研究,印度有27%的人讲北印度语。一位研究人员很好奇,如果他村里的数字更高。因此,他构筑了原假设和替代假设。他测试H0: p = 0.27。 HA: p> 0.27。在这里,p是该村讲北印度语的人口比例。他在自己的村庄进行了一项调查,以找出会讲北印度语的人数。他发现,在240位受访者中,有80位会说北印度语。如果我们假设满足必要条件且显着性水平为5%,则找出研究者测试的近似p值。
解决方案:
使用以下数据计算P值。

在这里,样本量n = 240,
p0 是人口比例我们将不得不找到样本比例 
= 80 / 240
 = 0.33
= 0.33
Z统计
Z统计量的计算


=0.33 – 0.27 / √ 0.27 * (1 – 0.27 ) / 240
Z统计将为–

ž = 2.093696
P值将是–

P值= P(z≥2.09)
我们必须看一下z表的值为2.09。因此,我们必须在z列中查看-2.0并在0.09列中查看该值。由于正态分布是对称的,因此曲线右侧的面积等于左侧的面积。我们得到的p值为0.0183。
P值 = 0.0183
由于p值小于0.05(5%)的显着水平,因此我们拒绝原假设。
笔记: 在Excel中,p值为0.0181
例子#3
研究表明,男性购买的机票数量比女性多。它们是由男性和女性以2:1的比例购买的。这项研究是在印度的一个特定机场进行的,目的是找出飞机票在男性和女性之间的分布。在150张门票中,男性购买了88张门票,女性购买了62张。我们需要找出实验操作是否导致结果变化,或者我们正在观察机会变化。假设显着度为0.05,则计算p值。
解决方案:
使用以下数据计算P值。

步骤1: 男性观察值为88,女性观察值为62。
- 男性预期值= 2/3 * 150 = 100男性
- 女性期望值= 1/3 * 150 = 50女性
第2步: 找出卡方


=((88-100)2)/100 + (62-50) 2/50
=1.44+2.88
卡方(X ^ 2)
卡方(X ^ 2)将为–

卡方(X ^ 2) = 4.32
第三步: 找到自由度
由于存在2个变量-男性和女性,因此n = 2
自由度= n-1 = 2-1 =
第4步: 从p值表中,我们可以看到表的第一行,因为自由度是1。我们可以看到p值在0.025到0.05之间。由于p值小于0.05的显着性,因此我们拒绝原假设。
P值将为–

P值 = 0.037666922
笔记: Excel使用以下公式直接给出p值:
CHITEST(实际范围,预期范围)
例子#4
众所周知,在城市中进入服装店的人中有60%会购买东西。一家服装店的老板想找到他所拥有的服装店的数量是否更高。他已经获得了为其商店进行的一项研究的结果。进入他的商店的200人中有128人购买了东西。商店老板以pas表示进入服装店并购买商品的人数比例。由他构架的原假设为p = 0.60,备用假设为p> 0.60。在显着性水平为5%的情况下找到该研究的p值。
解决方案:
使用以下数据计算P值。

在这里,样本数量n =200。我们将必须找到样本比例
= 128 / 200
 = 0.64
= 0.64
Z统计
Z统计量的计算


= 0.64 – 0.60 / √ 0.60 * (1 – 0.60) /200
Z统计将为–

Z统计 =1.1547
P值= P(z≥1.1547)
Excel中的NORMSDIST函数

NORMSDIST将是–

规范师 = 0.875893461
有一个内置函数可以根据Excel中的z统计量计算p值。它被称为NORMSDIST函数。 Excel NORMSDIST函数根据提供的值计算标准正态累积分布函数。其格式为NORMSDIST(z)。由于z统计值位于单元格B2中,因此使用的函数为= NORMSDIST(B2)。
P值将是–

P值 = 0.12410654
由于我们必须找到曲线右侧的面积,
p值= 1 – 0.875893 = 0.124107
由于0.124107的p值大于0.05的显着水平,因此我们无法拒绝原假设。
相关性和用途
P-Value在统计假设检验中具有广泛的应用,特别是在原假设检验中。例如,基金经理经营共同基金。他声称,共同基金的特定计划所产生的回报相当于基准股票市场指数Nifty。他会提出零假设,即共同基金计划的回报等于Nifty的回报。另一种假设是该计划的收益和Nifty收益不相等。然后,他将计算p值。