多重共线性(定义,类型)|带有说明的前3个示例
什么是多重共线性?
多重共线性是一种统计现象,其中回归模型中的两个或多个变量以其他方式依赖于其他变量,从而可以高度准确地从另一个变量线性预测一个变量。它通常用于观察性研究中,而在实验研究中则不那么受欢迎。
多重共线性的类型
多重共线性有四种类型
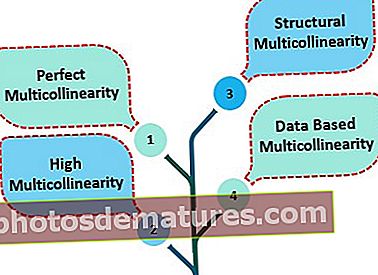
- #1 –完美的多重共线性 –当方程中的自变量预测理想的线性关系时存在。
- #2 –高多重共线性 –它是指两个或多个相互之间不完全相关的自变量之间的线性关系。
- #3 –结构多重共线性 –这是由研究人员本人在方程中插入不同的自变量引起的。
- #4 –基于数据的多重共性 –这是由研究人员设计不当的实验引起的。
共线性的原因
自变量,变量参数的变化确实会导致变量的微小变化,从而对结果产生重大影响,并且数据收集是指所选择的总体样本。
多重共线性的例子
范例#1
假设一家制药公司聘请了ABC Ltd KPO,以提供有关印度疾病的研究服务和统计分析。为此,ABC公司选择了年龄,体重,职业,身高和健康状况作为表面相貌参数。
- 在上面的示例中,存在多重共线性的情况,因为为研究选择的自变量与结果直接相关。因此,建议研究人员在开始任何项目之前先调整变量,因为这里选择的变量会直接影响结果。
范例#2
假设塔塔汽车公司已任命ABC Ltd,以了解塔塔汽车的销量在市场中的哪个类别中都很高。
- 在上述示例中,首先将确定需要完成研究的独立变量。它可以是月收入,年龄。品牌,下层阶级。这意味着只会选择适合所有这些选项卡的数据,以便找出有多少人甚至不用看其他汽车就能购买这辆车(tata nano)。
例子#3
假设聘用了ABC Ltd提交一份报告,以了解有多少50岁以下的人容易心脏病发作。为此,参数是年龄,性别,病史
- 在上面的示例中,出现了多重共线性,因为需要将自变量“年龄”调整为50岁以下才能邀请公众提出申请,以便自动过滤50岁以上的人。
好处
以下是一些优势
- 方程中自变量之间的线性关系。
- 在研究型公司准备的统计模型和研究报告中非常有用。
- 直接影响所需的结果。
缺点
以下是一些缺点
- 在某些情况下,可以通过收集有关变量的更多数据来解决此问题。
- 错误使用伪变量,即研究人员可能会在需要时忘记使用伪变量。
- 在方程式中插入2个相同或相同的变量,例如权重kg和lbs。
- 在方程中插入一个变量,该变量是2的组合。
- 由于它是统计技术,因此执行计算变得很复杂,并且需要统计计算器来执行。
结论
多重共线性是经常用于大型数据库和所需输出的回归分析和统计分析中的最受欢迎的统计工具之一。所有主要公司都在其公司中设有独立的统计部门,以对产品或人员进行统计回归分析,以便向管理层提供市场战略观点,并帮助他们起草长期战略。分析的图形表示形式为读者提供了直接关系,准确性和性能的清晰图片。
- 如果研究人员的目标是了解方程中的自变量,那么多重共线性将是他的大问题。
- 研究人员需要在阶段0本身对变量进行必要的更改,否则可能会对结果产生巨大影响。
- 可以通过检查相关矩阵来实现多重共线性。
- 补救措施在解决多重共线性问题中起着重要作用。